What is better than gradient descent?
 Liam Parker
Liam Parker 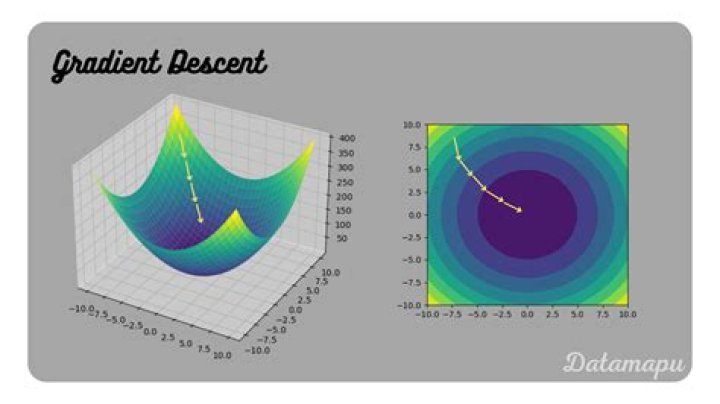
An interesting alternative to gradient descent is the population-based training algorithms such as the evolutionary algorithms (EA) and the particle swarm optimisation (PSO).
Is gradient descent the best?
Gradient descent is by far the most popular optimization strategy used in machine learning and deep learning at the moment. It is used when training data models, can be combined with every algorithm and is easy to understand and implement.Is SGD better than gradient descent?
SGD is stochastic in nature i.e it picks up a “random” instance of training data at each step and then computes the gradient making it much faster as there is much fewer data to manipulate at a single time, unlike Batch GD.Why is gradient descent Not enough?
It can be very slow for very large datasets because only one-time update for each epoch so large number of epochs is required to have a substantial number of updates. For large datasets, the vectorization of data doesn't fit into memory. For non-convex surfaces, it may only find the local minimums.What is the difference between backpropagation and gradient descent?
Back-propagation is the process of calculating the derivatives and gradient descent is the process of descending through the gradient, i.e. adjusting the parameters of the model to go down through the loss function.Tutorial 12- Stochastic Gradient Descent vs Gradient Descent
What is Adam Optimiser?
Adam is a replacement optimization algorithm for stochastic gradient descent for training deep learning models. Adam combines the best properties of the AdaGrad and RMSProp algorithms to provide an optimization algorithm that can handle sparse gradients on noisy problems.What is the difference between OLS and gradient descent?
Simple linear regression (SLR) is a model with one single independent variable. Ordinary least squares (OLS) is a non-iterative method that fits a model such that the sum-of-squares of differences of observed and predicted values is minimized. Gradient descent finds the linear model parameters iteratively.Is linear regression a gradient descent?
Gradient Descent Algorithm gives optimum values of m and c of the linear regression equation. With these values of m and c, we will get the equation of the best-fit line and ready to make predictions.Does SVD use gradient descent?
Singular value decomposition (SVD) is widely used technique to get low-rank factors of rating matrix and use Gradient Descent (GD) or Alternative Least Square (ALS) for optimization of its error objective function.Which is quite faster than batch gradient descent?
Stochastic Gradient Descent: This is a type of gradient descent which processes 1 training example per iteration. Hence, the parameters are being updated even after one iteration in which only a single example has been processed. Hence this is quite faster than batch gradient descent.Which is faster gradient descent or stochastic gradient descent?
Compared to Gradient Descent, Stochastic Gradient Descent is much faster, and more suitable to large-scale datasets. But since the gradient it's not computed for the entire dataset, and only for one random point on each iteration, the updates have a higher variance.Which one will you choose Gd or SGD Why?
SGD often converges much faster compared to GD but the error function is not as well minimized as in the case of GD. Often in most cases, the close approximation that you get in SGD for the parameter values are enough because they reach the optimal values and keep oscillating there.Why is Adam faster than SGD?
We show that Adam implicitly performs coordinate-wise gradient clipping and can hence, unlike SGD, tackle heavy-tailed noise. We prove that using such coordinate-wise clipping thresholds can be significantly faster than using a single global one. This can explain the superior perfor- mance of Adam on BERT pretraining.For what RNN is used and achieve the best results?
For what RNN is used and achieve the best results? Due it´s behavior, RNN is great to recognize handwriting and speech, calculating each input (letter/word or a second of a audio file for example), to find the correct outputs. Basically, RNN was made to process information sequences.What is CNN deep learning?
Convolutional Neural Networks (CNNs) Introduction. Deep Learning – which has emerged as an effective tool for analyzing big data – uses complex algorithms and artificial neural networks to train machines/computers so that they can learn from experience, classify and recognize data/images just like a human brain does.Which line is called the best fit line?
The regression line is sometimes called the “line of best fit” because it is the line that fits best when drawn through the points. It is a line that minimizes the distance of the actual scores from the predicted scores.Does ridge regression use gradient descent?
Gradient Descent from Scratch:When reg is larger than zero, the algorithm will produce results for ridge regression.